简介
正确使用数据处理、模型评估和模型算法选择技术无论是对机器学习学术研究还是工业场景应用都至关重要。
数据处理
在使用数据进行建模或分析之前,对其进行一定的处理;并且在应用机器学习算法分析结果之后对模型数据进行处理和特征提取/选择的过程。
数据标准化
数据离散化
数据抽样
数据降维
数据清理
相似度计算
模型评估与选择(简要一提)
模型评估
现实任务中,我们往往有许多算法可以选择,甚至对于同一个学习算法,使用不同的参数配置时,也会产生不同的模型。
然而在选择中,无法直接得到泛化误差,而训练误差又由于过拟合现象的存在不适合作为标准。所以我们通过增强模型泛化能力,得到适合进行 模型评估的泛化误差进行评估并进而做出选择。
性能度量
然而,对学习器的泛化性能进行评估,不仅需要有效可行的饰演顾及方法,还需要有衡量模型泛化能力的评价标准。这就是性能度量——模型评价方法。
应用机器学习算法建议(简要一提)
这些诊断法的执行和实现,是需要花些 时间的,有时候确实需要花很多时间来理解和实现,但这样做的确是把时间用在了刀刃上,因为这些方法让你在开发学习算法时,节省了几个月的时间。
构建一个学习算法的推荐方法(简要一提)
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法;(可以在一般的情况下 检验算法的有效性)
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择;
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。
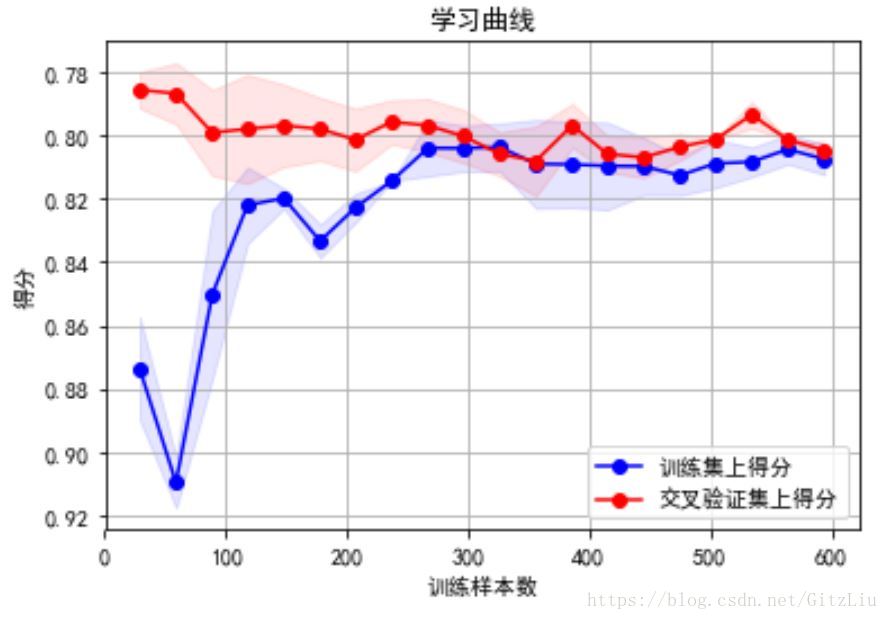
学习曲线(引出 特征提取和选择)
【简单来说】
学习曲线(learning curve)来判断模型状态:过拟合欠拟合
【详细来说】
学习曲线是不同训练集大小,模型在训练集和验证集上的得分变化曲线。也就是以样本数为横坐标,训练和交叉验证集上的得分(如准确率)为纵坐标。learning curve可以帮助我们判断模型现在所处的状态:过拟合(overfiting / high variance) or 欠拟合(underfitting / high bias)
模型欠拟合、过拟合、偏差和方差平衡 时对应的学习曲线如下图所示:

(1)左上角的图中训练集和验证集上的曲线能够收敛。在训练集合验证集上准确率相差不大,却都很差。这说明模拟对已知数据和未知都不能进行准确的预测,属于高偏差。这种情况模型很可能是欠拟合。可以针对欠拟合采取对应的措施。
欠拟合措施:
我们可以增加模型参数(特征),比如,构建更多的特征,减小正则项。
采用更复杂的模型
此时通过增加数据量是不起作用的。(为什么?)
(2)右上角的图中模型在训练集上和验证集上的准确率差距很大。说明模型能够很好的拟合已知数据,但是泛化能力很差,属于高方差。模拟很可能过拟合,要采取过拟合对应的措施。
过拟合措施:
我们可以增大训练集,降低模型复杂度,增大正则项,
或者通过特征选择减少特征数,即做一下feature selection,挑出较好的feature的subset来做training
(3)理想情况是找到偏差和方差都很小的情况,即收敛且误差较小。如右角的图。
LDA(区别于PCA)

排序:先重点-不紧急(但是 重要且有用!)其它放这里。
| 23:00-24:00 | 7:00-8:30 | 8:30:10:00 | 10:10-11:40 | 11:40-14:00 | 14:00-15:10 | 15:20-17:20 | 17:20-18:30 | 18:30-20:30 | 20:30-21:30 |
|---|---|---|---|---|---|---|---|---|---|
| 睡觉 | 起床吃饭+英语 | 基础+第三周 | CNN | 午休 | 上课(花书) | 上课(花书) | 吃饭+打印 | 整理上午+CNN笔记 | 总结+计划/ |
| 买书? | 上传/输出blog | ||||||||

